
1.1 MHA简介
1.1.1 MHA软件介绍
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在10~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制 框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的 replication中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现 有的复制部署也是它的优势之处。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中 (通过将从库提升为主库),大概0.5-2秒内即可完成。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。
MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
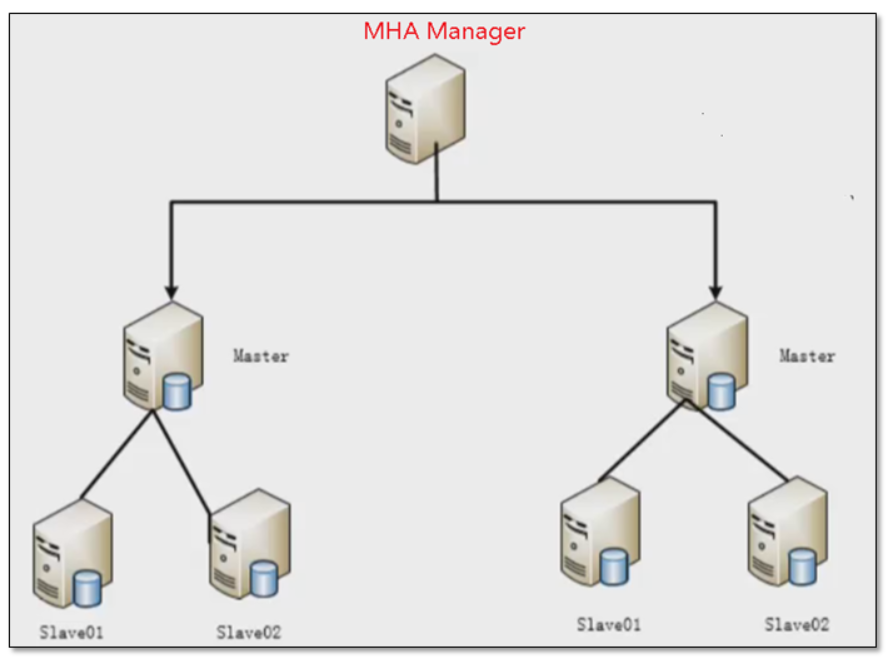
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
1.1.2 MHA工作原理
 | 工作原理说明: 1、保存master上的所有binlog事件 2、找到含有最新binlog位置点的slave 3、通过中继日志将数据恢复到其他的slave 4、将包含最新binlog位置点的slave提升为master 5、将其他从库slave指向新的master原slave01 并开启主从复制 6、将保存下来的binlog恢复到新的master上 |
|---|---|
1、监控所有node节点MHA功能说明:
2、自动故障切换(failover)
前提是必须有三个节点存在,并且有两个从库
(1)选主前提,按照配置文件的顺序进行,但是如果此节点后主库100M以上relay-log 就不会选
(2)如果你设置了权重,总会切换带此节点;一般在多地多中心的情况下,一般会把权重设置在本地节点。
(3)选择s1为新主
(4)保存主库binlog日志
3、重新构建主从
(1)将有问题的节点剔除MHA
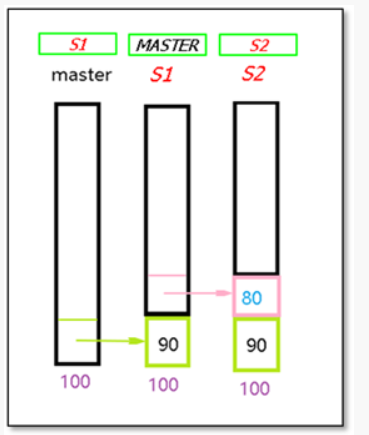
进行第一阶段数据补偿,S2缺失部分补全90
(2)s1切换角色为新主,将s2指向新主S1
s2 change master to s1
(3) 第二阶段数据补偿
将保存过来的新主和原有主缺失部分的binlog,应用到新主。
(4)虚拟IP漂移到新主,对应用透明无感知
(5)通知管理员故障切换
1.1.3 MHA高可用架构图
1.1.4 MHA工具介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下:
Manager工具包主要包括以下几个工具:
masterha_check_ssh #检査 MHA 的 ssh-key^masterha_check_repl #检査主从复制情况masterha_manger #启动MHAmasterha_check_status #检测MHA的运行状态^masterha_mast er_monitor #检测master是否宕机一masterha_mast er_switch #手动故障转移—masterha_conf_host #手动添加server倍息一masterha_secondary_check #建立TCP连接从远程服务器vmasterha_stop #停止MHANode工具包主要包括以下几个工具:
save_binary_1ogs #保存宕机的master的binlogapply_diff_relay_logs #识别relay log的差异filter_mysqlbinlog #防止回滚事件一MHA已不再使用这个工具purge_relay_logs #清除中继曰志一不会阻塞SQL线程1.1.5 MHA的优点
1、自动故障转移
2、主库崩溃不存在数据不一致的情况
3、不需要对当前的mysql环境做重大修改
4、不需要添加额外的服务器
5、性能优秀,可以工作再半同步和异步复制框架
6、只要replication支持的存储引擎mha都支持
1.2 环境说明
在本次的实验中,共需要用到三台主机,系统、软件说明如下。
1.2.1 系统环境说明
db01主机(master)
[root@db01 ~]# cat /etc/redhat-release CentOS release 6.9 (Final)[root@db01 ~]# uname -r2.6.32-696.el6.x86_64[root@db01 ~]# /etc/init.d/iptables statusiptables: Firewall is not running.[root@db01 ~]# getenforce Disabled[root@db01 ~]# hostname -I10.0.0.51 172.16.1.51db02主机(slave1)
1 [root@db02 ~]# cat /etc/redhat-release 2 CentOS release 6.9 (Final) 3 [root@db02 ~]# uname -r 4 2.6.32-696.el6.x86_64 5 [root@db02 ~]# /etc/init.d/iptables status 6 iptables: Firewall is not running. 7 [root@db02 ~]# getenforce 8 Disabled 9 [root@db02 ~]# hostname -I10 10.0.0.52 172.16.1.52db03主机(slave1,MHA Manages、Atlas节点)
1 [root@db02 ~]# cat /etc/redhat-release 2 CentOS release 6.9 (Final) 3 [root@db02 ~]# uname -r 4 2.6.32-696.el6.x86_64 5 [root@db02 ~]# /etc/init.d/iptables status 6 iptables: Firewall is not running. 7 [root@db02 ~]# getenforce 8 Disabled 9 [root@db02 ~]# hostname -I10 10.0.0.52 172.16.1.521.2.2 mysql软件说明
三台服务器上都全新安装mysql 5.6.36 :
[root@db01 ~]# mysql --versionmysql Ver 14.14 Distrib 5.6.36, for Linux (x86_64) using EditLine wrapper关于mysql数据库具体的安装方法参考 id="13-基于gtid的主从复制配置">1.3 基于GTID的主从复制配置
1.3.1 先决条件
🔊 主库和从库都要开启binlog
🔊 主库和从库server-id必须不同
🔊 要有主从复制用户
1.3.2 配置主从复制
db01 my.cnf****文件
[root@db01 ~]# cat /etc/my.cnf[mysqld]basedir=/application/mysqldatadir=/application/mysql/datasocket=/tmp/mysql.socklog-error=/var/log/mysql.loglog-bin=/data/mysql/mysql-binbinlog_format=rowsecure-file-priv=/tmp server-id=51skip-name-resolve # 跳过域名解析gtid-mode=on # 启用gtid类型,否则就是普通的复制架构enforce-gtid-consistency=true #强制GTID的一致性log-slave-updates=1 # slave更新是否记入日志(5.6必须的)relay_log_purge = 0 [mysql]socket=/tmp/mysql.sockdb02 my.cnf****文件
1 [root@db02 ~]# cat /etc/my.cnf 2 [mysqld] 3 basedir=/application/mysql 4 datadir=/application/mysql/data 5 socket=/tmp/mysql.sock 6 log-error=/var/log/mysql.log 7 log-bin=/data/mysql/mysql-bin 8 binlog_format=row 9 secure-file-priv=/tmp 10 server-id=5211 skip-name-resolve12 gtid-mode=on13 enforce-gtid-consistency=true14 log-slave-updates=115 relay_log_purge = 0 16 [mysql]17 socket=/tmp/mysql.sockdb03 my.cnf****文件
1 [root@db03 ~]# cat /etc/my.cnf 2 [mysqld] 3 basedir=/application/mysql 4 datadir=/application/mysql/data 5 socket=/tmp/mysql.sock 6 log-error=/var/log/mysql.log 7 log-bin=/data/mysql/mysql-bin 8 binlog_format=row 9 secure-file-priv=/tmp 10 server-id=5311 skip-name-resolve12 gtid-mode=on13 enforce-gtid-consistency=true14 log-slave-updates=115 relay_log_purge = 0 16 skip-name-resolve17 [mysql]18 socket=/tmp/mysql.sock创建复制用户 (51作为主节点,52、53为从)
GRANT REPLICATION SLAVE ON *.* TO repl@'10.0.0.%' IDENTIFIED BY '123';从库开启复制
change master to master_host='10.0.0.51', master_user='repl', master_password='123', MASTER_AUTO_POSITION=1;启动从库复制
start slave;1.3.3 GTID复制技术说明
MySQL GTID****简介
GTID的全称为 global transaction identifier ,可以翻译为全局事务标示符,GTID在原始master上的事务提交时被创建。GTID需要在全局的主-备拓扑结构中保持唯一性,GTID由两部分组成:
GTID = source_id:transaction_id
source_id用于标示源服务器,用server_uuid来表示,这个值在第一次启动时生成,并写入到配置文件data/auto.cnf中
transaction_id则是根据在源服务器上第几个提交的事务来确定。
GTID**事件结构

GTID**在二进制日志中的结构
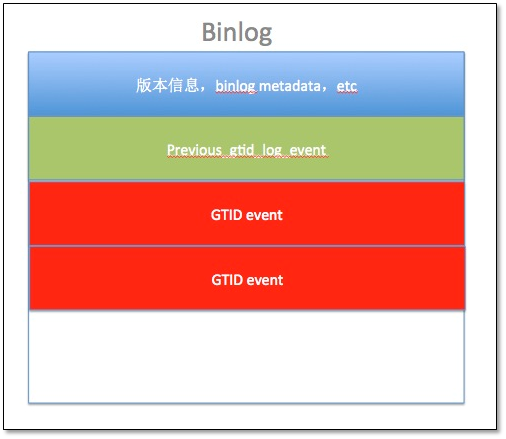
一个GTID*的生命周期包括:*
1.事务在主库上执行并提交给事务分配一个gtid(由主库的uuid和该服务器上未使用的最小事务序列号),该GTID被写入到binlog中。
2.备库读取relaylog中的gtid,并设置session级别的gtid_next的值,以告诉备库下一个事务必须使用这个值
3.备库检查该gtid是否已经被其使用并记录到他自己的binlog中。slave需要担保之前的事务没有使用这个gtid,也要担保此时已分读取gtid,但未提交的事务也不恩呢过使用这个gtid.
4.由于gtid_next非空,slave不会去生成一个新的gtid,而是使用从主库获得的gtid。这可以保证在一个复制拓扑中的同一个事务gtid不变。由于GTID在全局的唯一性,通过GTID,我们可以在自动切换时对一些复杂的复制拓扑很方便的提升新主库及新备库,例如通过指向特定的GTID来确定新备库复制坐标。
GTID是用来替代以前classic的复制方法;
MySQL5.6.2支持 MySQL5.6.10后完善;
GTID****相比传统复制的优点:
1.一个事务对应一个唯一ID,一个GTID在一个服务器上只会执行一次
2.GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置
3.减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机
GTID****的限制:
1.不支持非事务引擎
2.不支持create table ... select 语句复制(主库直接报错)
原理:( 会生成两个sql,一个是DDL创建表SQL,一个是insert into 插入数据的sql。
由于DDL会导致自动提交,所以这个sql至少需要两个GTID,但是GTID模式下,只能给这个sql生成一个GTID )
3.不允许一个SQL同时更新一个事务引擎表和非事务引擎表
4.在一个复制组中,必须要求统一开启GTID或者是关闭GTID
5.开启GTID需要重启(5.7除外)
6.开启GTID后,就不再使用原来的传统复制方式
7.对于create temporary table 和 drop temporary table语句不支持
8.不支持sql_slave_skip_counter
1.3.4 COM_BINLOG_DUMP_GTID
从机发送到主机执行的事务的标识符的主范围
Master send all other transactions to slave
同样的GTID不能被执行两次,如果有同样的GTID,会自动被skip掉。
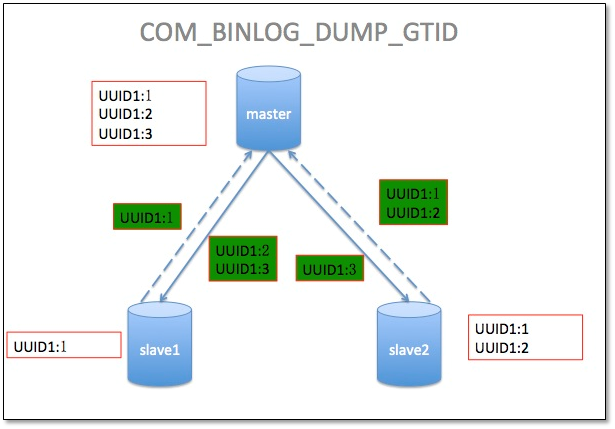
slave1:将自己的UUID1:1发送给master,然后接收到了UUID1:2,UUID1:3 event
slave2:将自己的UUID1:1,UUID1:2发送给master,然后接收到了UUID1:3事件
GTID****组成
GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增
GTID = source_id :transaction_id7E11FA47-31CA-19E1-9E56-C43AA21293967:291.3.5 【示例二】MySQL GTID复制配置
主节点my.cnf文件
# vi /etc/my.cnf[mysqld]basedir=/usr/local/mysqldatadir=/data/mysqlserver-id=1log-bin=mysql-binsocket=/tmp/mysql.sockbinlog-format=ROWgtid-mode=onenforce-gtid-consistency=truelog-slave-updates=1从节点my.cnf文件
# vi /etc/my.cnf[mysqld]basedir=/usr/local/mysqldatadir=/data/mysqlserver-id=2binlog-format=ROWgtid-mode=onenforce-gtid-consistency=truelog-bin=mysql-binlog_slave_updates = 1socket=/tmp/mysql.sock配置文件注解
server-id=x # 同一个复制拓扑中的所有服务器的id号必须惟一binlog-format=RO # 二进制日志格式,强烈建议为ROWgtid-mode=on # 启用gtid类型,否则就是普通的复制架构enforce-gtid-consistency=true # 强制GTID的一致性log-slave-updates=1 # slave更新是否记入日志复制用户准备(Master主节点)
mysql>GRANT REPLICATION SLAVE ON *.* TO rep@'10.0.0.%' IDENTIFIED BY '123';开启复制(Slave从节点)
mysql>start slave;mysql>show slave status\G现在就可以进行主从复制测试。
1.4 部署MHA
本次MHA的部署基于GTID复制成功构建,普通主从复制也可以构建MHA架构。
1.4.1 环境准备(所有节点操作)
安装依赖包
yum install perl-DBD-MySQL -y下载mha软件,mha官网:https://code.google.com/archive/p/mysql-master-ha/
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
*下载软件包*
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
在所有节点安装node
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm创建mha管理用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';# 主库上创建,从库会自动复制(在从库上查看)
创建命令软连接(重要)
如果不创建命令软连接,检测mha复制情况的时候会报错
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlogln -s /application/mysql/bin/mysql /usr/bin/mysql1.4.2 部署管理节点(mha-manager)
在mysql-db03上部署管理节点
# 安装epel源,软件需要wget -O /etc/yum.repos.d/epel.repo # 安装manager 依赖包yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes# 安装manager管理软件rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm创建必须目录
mkdir -p /etc/mhamkdir -p /var/log/mha/app1 ----》可以管理多套主从复制编辑mha-manager*配置文件*
[root@db03 ~]# cat /etc/mha/app1.cnf[server default] manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysqluser=mhapassword=mhaping_interval=2repl_password=123repl_user=replssh_user=root[server1]hostname=10.0.0.51port=3306[server2]hostname=10.0.0.52port=3306[server3]hostname=10.0.0.53port=3306【配置文件详解】
[server default] 2 #设置manager的工作目录 3 manager_workdir=/var/log/masterha/app1 4 #设置manager的日志 5 manager_log=/var/log/masterha/app1/manager.log 6 #设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录 7 master_binlog_dir=/data/mysql 8 #设置自动failover时候的切换脚本 9 master_ip_failover_script= /usr/local/bin/master_ip_failover10 #设置手动切换时候的切换脚本11 master_ip_online_change_script= /usr/local/bin/master_ip_online_change12 #设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码13 password=12345614 #设置监控用户root15 user=root16 #设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover17 ping_interval=118 #设置远端mysql在发生切换时binlog的保存位置19 remote_workdir=/tmp20 #设置复制用户的密码21 repl_password=12345622 #设置复制环境中的复制用户名 23 repl_user=rep24 #设置发生切换后发送的报警的脚本25 report_script=/usr/local/send_report26 #一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server0227 secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=10.0.0.51 --master_port=330628 #设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)29 shutdown_script=""30 #设置ssh的登录用户名31 ssh_user=root 32 33 [server1]34 hostname=10.0.0.5135 port=330636 37 [server2]38 hostname=10.0.0.5239 port=330640 #设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave41 candidate_master=142 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master43 check_repl_delay=0配置ssh信任(密钥分发,在所有节点上执行)
# 生成密钥ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1# 分发公钥,包括自己for i in 1 2 3 ;do ssh-copy-id -i /root/.ssh/id_dsa.pub root@10.0.0.5$i ;done 分发完成后测试分发是否成功
for i in 1 2 3 ;do ssh 10.0.0.5$i date ;done或[root@db03 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf最后一行信息为如下字样即为分发成功:Thu Dec 28 18:44:53 2017 - [info] All SSH connection tests passed successfully.1.4.3 启动mha
经过上面的部署过后,mha架构已经搭建完成
# 启动mhanohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 & 启动成功后,检查主库状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:3298) is running(0:PING_OK), master:10.0.0.511.4.4 切换master测试
查看现在的主库是哪个
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:11669) is running(0:PING_OK), master:10.0.0.51手动停止主库
[root@db01 ~]# /etc/init.d/mysqld stop Shutting down MySQL..... SUCCESS!再停止数据的同时查看日志信息的变化
[root@db03 ~]# tailf /var/log/mha/app1/manager~~~Fri Dec 29 15:51:14 2017 - [info] All other slaves should start replication fromhere. Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';修复主从
① 启动原主库,添加change master to 信息
[root@db01 ~]# /etc/init.d/mysqld start Starting MySQL. SUCCESS!mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';mysql> start slave;② 查看主从复制状态
mysql> show slave status\G Master_Host: 10.0.0.52 Slave_IO_Running: Yes Slave_SQL_Running: Yes修复mha
① 修改app1.cnf配置文件,添加回被剔除主机
[root@db03 ~]# cat /etc/mha/app1.cnf [binlog1]hostname=10.0.0.53master_binlog_dir=/data/mysql/binlog/no_master=1[server default]manager_log=/var/log/mha/app1/managermanager_workdir=/var/log/mha/app1master_binlog_dir=/data/mysqlmaster_ip_failover_script=/usr/local/bin/master_ip_failoverpassword=mhaping_interval=2repl_password=123repl_user=replssh_user=rootuser=mha[server1]hostname=10.0.0.51port=3306[server2]hostname=10.0.0.52port=3306[server3]hostname=10.0.0.53port=3306② mha检查复制状态
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnfMySQL Replication Health is OK.③ 启动mha程序
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &到此主库切换成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf app1 (pid:11978) is running(0:PING_OK), master:10.0.0.52实验结束将主库切换回db01.
① 停止mha
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf Stopped app1 successfully.② 停止所有从库slave(所有库操作)
stop slave;reset slave all;③ 重做主从复制(db02、db03)
CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';④ 启动slave
start slave; 启动之后检查从库是否为两个yes show slave status\G
⑤ mha检查主从复制
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnfMySQL Replication Health is OK.⑥ 启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &检查切换是否成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnfapp1 (pid:12127) is running(0:PING_OK), master:10.0.0.51 到此主主节点有切回到db01
1.4.5 设置权重
修改[server1]的权重
[server1]hostname=10.0.0.51port=3306candidate_master=1check_repl_delay=0配置说明
candidate_master=1 ----》不管怎样都切到优先级高的主机,一般在主机性能差异的时候用 check_repl_delay=0 ----》不管优先级高的备选库,数据延时多久都要往那切注:
1、多地多中心,设置本地节点为高权重
2、在有半同步复制的环境中,设置半同步复制节点为高权重
3、你觉着哪个机器适合做主节点,配置较高的 、性能较好的
1.5 配置VIP漂移
1.5.1 IP漂移的两种方式
🐶 通过keepalived的方式,管理虚拟IP的漂移
🐶 通过MHA自带脚本方式,管理虚拟IP的漂移
1.5.2 MHA脚本方式
修改mha****配置文件
[root@db03 ~]# grep "script" /etc/mha/app1.cnf [server default]master_ip_failover_script=/usr/local/bin/master_ip_failover 再主配置中添加VIP脚本
脚本内容
[root@db03 ~]# cat /usr/local/bin/master_ip_failover #!/usr/bin/env perluse strict;use warnings FATAL => 'all';use Getopt::Long;my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port);my $vip = '10.0.0.55/24';my $key = '0';my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port,);exit &main();sub main { print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n"; if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n"; exit 0; } else { &usage(); exit 1; }}sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}sub stop_vip() { return 0 unless ($ssh_user); `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";}该脚本为软件自带,脚本获取方法:再mha源码包中的samples目录下有该脚本的模板,对该模板进行修改即可使用。路径如: mha4mysql-manager-0.56/samples/scripts
脚本修改内容
my $vip = '10.0.0.55/24';my $key = '0';my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";脚本添加执行权限否则mha无法启动
chmod +x /usr/local/bin/master_ip_failover手动绑定VIP(****主库)
ifconfig eth0:0 10.0.0.55/24检查
[root@db01 ~]# ip a s eth02: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:6c:7a:11 brd ff:ff:ff:ff:ff:ff inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0 inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0 inet6 fe80::20c:29ff:fe6c:7a11/64 scope link valid_lft forever preferred_lft forever 至此vip****漂移配置完成
1.5.3 测试虚拟IP漂移
查看db02的slave信息
 View Code 现在主从状态
View Code 现在主从状态
停掉主库
[root@db01 ~]# /etc/init.d/mysqld stop在db03上查看从库slave信息
View Code 停掉主库后的主从信息
在db01上查看vip信息
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:6c:7a:11 brd ff:ff:ff:ff:ff:ff inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0 inet6 fe80::20c:29ff:fe6c:7a11/64 scope link valid_lft forever preferred_lft forever在db02上查看vip信息
[root@db02 ~]# ip a s eth02: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:d6:0a:b3 brd ff:ff:ff:ff:ff:ff inet 10.0.0.52/24 brd 10.0.0.255 scope global eth0inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0 inet6 fe80::20c:29ff:fed6:ab3/64 scope link valid_lft forever preferred_lft forever 至此,VIP漂移就测试成功
1.6 配置binlog-server
1.6.1 配置binlog-server
1)前期准备:
1、准备一台新的mysql实例(db03),GTID必须开启。
2、将来binlog接收目录,不能和主库binlog目录一样
2)停止mha
masterha_stop --conf=/etc/mha/app1.cnf3)在app1.cnf开启binlogserver功能
[binlog1] no_master=1 hostname=10.0.0.53 ----> 主机DB03 master_binlog_dir=/data/mysql/binlog/ ----> binlog保存目录4)开启binlog接收目录,注意权限
mkdir -p /data/mysql/binlog/ chown -R mysql.mysql /data/mysql# 进入目录启动程序 cd /data/mysql/binlog/ &&\ mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &参数说明:-R 远程主机
5)启动mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &1.6.2 测试binlog备份
#查看binlog目录中的binlog
[root@db03 binlog]# lltotal 44-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001#登录主库
[root@mysql-db01 ~]# mysql -uroot -p123#刷新binlog
mysql> flush logs;#再次查看binlog目录
[root@db03 binlog]# lltotal 48-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001-rw-r--r-- 1 root root 143 Mar 8 04:00 mysql-bin.0000021.7 mysql中间件Atlas
1.7.1 atlas简介
Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。目前该项目在360公司内部得到了广泛应用,很多MySQL业务已经接入了Atlas平台,每天承载的读写请求数达几十亿条。
同时,有超过50家公司在生产环境中部署了Atlas,超过800人已加入了我们的开发者交流群,并且这些数字还在不断增加。而且安装方便。配置的注释写的蛮详细的,都是中文。
Atlas官方链接: https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
Atlas下载链接: https://github.com/Qihoo360/Atlas/releases
1.7.2 主要功能
读写分离、从库负载均衡、自动分表、IP过滤
SQL语句黑白名单、DBA可平滑上下线DB、自动摘除宕机的DB
Atlas相对于官方MySQL-Proxy的优势
1.将主流程中所有Lua代码用C重写,Lua仅用于管理接口
2.重写网络模型、线程模型
3.实现了真正意义上的连接池
4.优化了锁机制,性能提高数十倍
1.7.3 使用场景
Atlas是一个位于前端应用与后端MySQL数据库之间的中间件,它使得应用程序员无需再关心读写分离、分表等与MySQL相关的细节,可以专注于编写业务逻辑,同时使得DBA的运维工作对前端应用透明,上下线DB前端应用无感知。
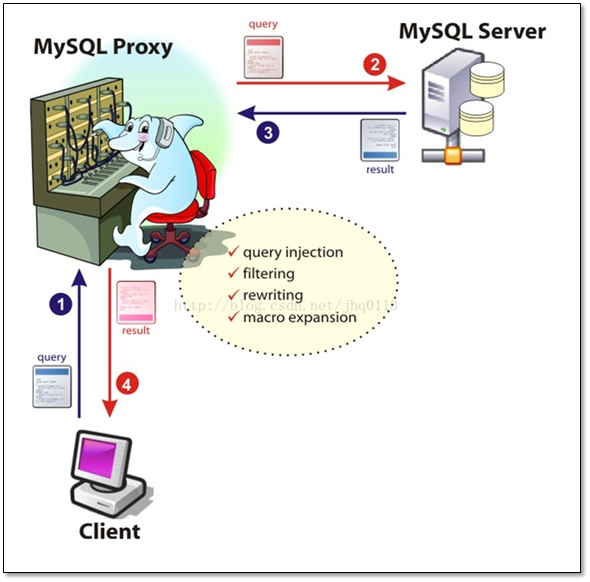
Atlas是一个位于应用程序与MySQL之间中间件。在后端DB看来,Atlas相当于连接它的客户端,在前端应用看来,Atlas相当于一个DB。
Atlas作为服务端与应用程序通讯,它实现了MySQL的客户端和服务端协议,同时作为客户端与MySQL通讯。它对应用程序屏蔽了DB的细节,同时为了降低MySQL负担,它还维护了连接池.
1.7.4 企业读写分离及分库分表其他方案介绍
Mysql-proxy(oracle)
Mysql-router(oracle)
Atlas (Qihoo 360)
Atlas-sharding (Qihoo 360)
Cobar(是阿里巴巴(B2B)部门开发)
Mycat(基于阿里开源的Cobar产品而研发)
TDDL Smart Client的方式(淘宝)
Oceanus(58同城数据库中间件)
OneProxy(原支付宝首席架构师楼方鑫开发 )
vitess(谷歌开发的数据库中间件)
Heisenberg(百度)
TSharding(蘑菇街白辉)
Xx-dbproxy(金山的Kingshard、当当网的sharding-jdbc )
amoeba
1.7.5 安装Atlas
软件获取地址:https://github.com/Qihoo360/Atlas/releases
注意:
1、Atlas只能安装运行在64位的系统上
2、Centos 5.X安装 Atlas-XX.el5.x86_64.rpm,Centos 6.X安装Atlas-XX.el6.x86_64.rpm。
3、后端mysql版本应大于5.1,建议使用Mysql 5.6以上
Atlas (普通) : Atlas-2.2.1.el6.x86_64.rpm
Atlas (分表) : Atlas-sharding_1.0.1-el6.x86_64.rpm
下载安装atlas
wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpmrpm -ivh Atlas-2.2.1.el6.x86_64.rpm 至此安装完成
1.7.6 配置Atlas配置文件
atlas配置文件中的密码需要加密,可以使用,软件自带的加密工具进行加密
cd /usr/local/mysql-proxy/conf//usr/local/mysql-proxy/bin/encrypt 密码 ---->制作加密密码生产密文密码:
[root@db03 bin]# /usr/local/mysql-proxy/bin/encrypt 1233yb5jEku5h4=[root@db03 bin]# /usr/local/mysql-proxy/bin/encrypt mhaO2jBXONX098=编辑配置文件
vim /usr/local/mysql-proxy/conf/test.cnf[mysql-proxy]admin-username = useradmin-password = pwdproxy-backend-addresses = 10.0.0.55:3306proxy-read-only-backend-addresses = 10.0.0.52:3306,10.0.0.53:3306pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098=daemon = truekeepalive = trueevent-threads = 8log-level = messagelog-path = /usr/local/mysql-proxy/logsql-log=ONproxy-address = 0.0.0.0:33060admin-address = 0.0.0.0:2345charset=utf8配置文件内为全中文注释,这里有一份较为详细的解释:
View Code Atlas配置文件说明
1.7.7 启动Atlas
编写一个atlas的管理脚本,当然也可以写脚本,可以直接手动的管理:
/usr/local/mysql-proxy/bin/mysql-proxyd test start #启动/usr/local/mysql-proxy/bin/mysql-proxyd test stop #停止/usr/local/mysql-proxy/bin/mysql-proxyd test restart #重启注意:test是配置文件的名称
脚本内容:
View Code Atas管理脚本
检查端口是否正常
[root@db03 ~]# netstat -lntup|grep mysql-proxytcp 0 0 0.0.0.0:33060 0.0.0.0:* LISTEN 2125/mysql-proxy tcp 0 0 0.0.0.0:2345 0.0.0.0:* LISTEN 2125/mysql-proxy1.7.8 Atlas管理操作
登入管理接口
[root@db03 ~]# mysql -uuser -ppwd -h127.0.0.1 -P2345查看帮助信息
mysql> SELECT * FROM help;查看后端的代理库
mysql> SELECT * FROM backends;+-------------+----------------+-------+------+| backend_ndx | address | state | type |+-------------+----------------+-------+------+| 1 | 10.0.0.55:3306 | up | rw || 2 | 10.0.0.52:3306 | up | ro || 3 | 10.0.0.53:3306 | up | ro |+-------------+----------------+-------+------+3 rows in set (0.00 sec)平滑摘除mysql
mysql> REMOVE BACKEND 2;Empty set (0.00 sec)检查是否摘除
mysql> SELECT * FROM backends;+-------------+----------------+-------+------+| backend_ndx | address | state | type |+-------------+----------------+-------+------+| 1 | 10.0.0.55:3306 | up | rw || 2 | 10.0.0.53:3306 | up | ro |+-------------+----------------+-------+------+2 rows in set (0.00 sec)保存到配置文件中
mysql> SAVE CONFIG;将节点再添加回来
mysql> add slave 10.0.0.52:3306;Empty set (0.00 sec)查看是否添加成功
mysql> SELECT * FROM backends;+-------------+----------------+-------+------+| backend_ndx | address | state | type |+-------------+----------------+-------+------+| 1 | 10.0.0.55:3306 | up | rw || 2 | 10.0.0.53:3306 | up | ro || 3 | 10.0.0.52:3306 | up | ro |+-------------+----------------+-------+------+3 rows in set (0.00 sec)保存到配置文件中
mysql> SAVE CONFIG;1.7.9 连接数据库查看负载
通过atlas登陆数据,注意,使用的是数据库上的用户及密码
shell> mysql -umha -pmha -h127.0.0.1 -P33060第一次查询server_id
mysql> show variables like "server_id";+---------------+-------+| Variable_name | Value |+---------------+-------+| server_id | 53 |+---------------+-------+1 row in set (0.00 sec)第二次查询server_id
mysql> show variables like "server_id";+---------------+-------+| Variable_name | Value |+---------------+-------+| server_id | 52 |+---------------+-------+1 row in set (0.00 sec) *通过上面可以看到负载成功*
1.7.10 读写分离的说明
Atlas会透明的将事务语句和写语句发送至主库执行,读语句发送至从库执行。具体以下语句会在主库执行:
显式事务中的语句
autocommit=0时的所有语句
含有select GET_LOCK()的语句
除SELECT、SET、USE、SHOW、DESC、EXPLAIN外的。
从库负载均衡配置
proxy-read-only-backend-addresses=ip1:port1@权重,ip2:port2@权重1.7.11 Atlas高级功能
自动分表
使用Atlas的分表功能时,首先需要在配置文件test.cnf设置tables参数。
tables参数设置格式:数据库名.表名.分表字段.子表数量,比如:
你的数据库名叫school,表名叫stu,分表字段叫id,总共分为2张表,那么就写为school.stu.id.2,如果还有其他的分表,以逗号分隔即可。
用户需要手动建立2张子表(stu_0,stu_1,注意子表序号是从0开始的)。
所有的子表必须在DB的同一个database里。
当通过Atlas执行(SELECT、DELETE、UPDATE、INSERT、REPLACE)操作时,Atlas会根据分表结果(id%2=k),定位到相应的子表(stu_k)。
例如,执行select * from stu where id=3;,Atlas会自动从stu_1这张子表返回查询结果。
但如果执行SQL语句(select * from stu;)时不带上id,则会提示执行stu表不存在。
Atles功能的说明
Atlas暂不支持自动建表和跨库分表的功能。
Atlas目前支持分表的语句有SELECT、DELETE、UPDATE、INSERT、REPLACE。
IP****过滤:client-ips
该参数用来实现IP过滤功能。
在传统的开发模式中,应用程序直接连接DB,因此DB会对部署应用的机器(比如web服务器)的IP作访问授权。
在引入中间层后,因为连接DB的是Atlas,所以DB改为对部署Atlas的机器的IP作访问授权,如果任意一台客户端都可以连接Atlas,就会带来潜在的风险。
client-ips参数用来控制连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔写在一行上即可。
如: client-ips=192.168.1.2, 192.168.2
这就代表192.168.1.2这个IP和192.168.2.*这个段的IP可以连接Atlas,其他IP均不能连接。如果该参数不设置,则任意IP均可连接Atlas。如果设置了client-ips参数,且Atlas前面挂有LVS,则必须设置lvs-ips参数,否则可以不设置lvs-ips。
SQL****语句黑白名单功能: Atlas会屏蔽不带where条件的delete和update操作,以及sleep函数。
1.8 Atlas-Sharding版本
1.8.1 版本介绍
Sharding的基本思想就是把一个数据表中的数据切分成多个部分, 存放到不同的主机上去(切分的策略有多种), 从而缓解单台机器的性能跟容量的问题.
sharding是一种水平切分, 适用于单表数据庞大的情景. 目前atlas支持静态的
sharding方案, 暂时不支持数据的自动迁移以及数据组的动态加入.
Atlas以表为单位sharding, 同一个数据库内可以同时共有sharding的表和不sharding的表, 不sharding的表数据存在未sharding的数据库组中.
目前Atlas sharding支持insert, delete, select, update语句, 只支持不跨shard的事务. 所有的写操作如insert, delete, update只能一次命中一个组, 否则会报"ERROR 1105 (HY000):write operation is only allow to one dbgroup!"错误.
由于sharding取替了Atlas的分表功能, 所以在Sharding分支里面, Atlas单机分表的功能已经移除, 配置tables将不会再有效.
1.8.2 Atlas-Sharding架构
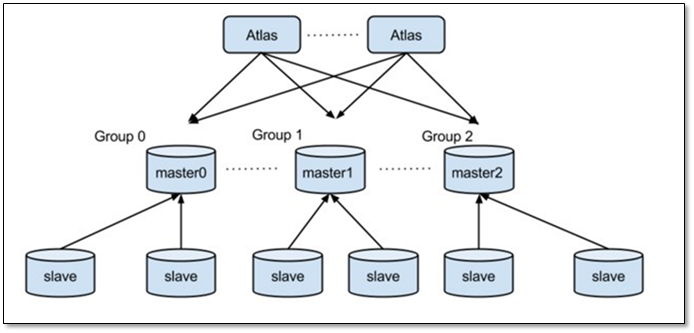
1.8.3 Sharding配置示例
Atlas支持非sharding跟sharding的表共存在同一个Atlas中, 2.2.1之前的配置可以直接运行. 之前的配置如
proxy-backend-addresses = 192.168.0.12:3306proxy-read-only-backend-addresses = 192.168.0.13:3306,192.168.0.14:3306 ... 这配置了一个master和两个slave,这属于非sharding的组, 所有非sharding的表跟语句都会发往这个组内.
所以之前没有Sharding的Atlas的表可以无缝的在新版上使用,
注意: 非Sharding的组只能配置一个, 而sharding的组可以配置多个. 下面的配置, 配置了Sharding的组, 注意与上面的配置区分
[shardrule-0]table = test.sharding_test分表名,有数据库+表名组成 t
ype = rangesharding类型:range 或 hash
shard-key = idsharding 字段
groups = 0:0-999,1:1000-1999分片的group,如果是range类型的sharding,则groups的格式是:group_id:id范围。如果是hash类型的sharding,则groups的格式是:group_id。例如groups = 0, 1
[group-0]proxy-backend-addresses=192.168.0.15:3306proxy-read-only-backend-addresses=192.168.0.16:3306[group-1]proxy-backend-addresses=192.168.0.17:3306proxy-read-only-backend-addresses=192.168.0.18:33061.8.4 Sharding限制
关于支持的语句
Atlas sharding只对sql语句提供有限的支持, 目前支持基本的Select, insert/replace, delete,update语句,支持全部的Where语法(SQL-92标准), 不支持DDL(create drop alter)以及一些管理语句,DDL请直连MYSQL执行, 请只在Atlas上执行Select, insert, delete, update(CRUD)语句.
对于以下语句, 如果语句命中了多台dbgroup, Atlas均未做支持(如果语句只命中了一个dbgroup, 如 select count(*) from test where id < 1000, 其中dbgroup0范围是0 - 1000, 那么这些特性都是支持的)Limit Offset(支持Limit)
Order by
Group by Join
ON
Count, Max, Min等函数
增加节点
注意: 暂时只支持range方式的节点扩展, hash方式由于需要数据迁移, 暂时未做支持.
扩展节点在保证原来节点的范围不改变的情况下, 如已有dbgroup0为范围0 - 999, dbgroup1为范围 1000-1999, 这个时候可以增加范围>2000的节点. 如增加一个节点为2000 - 2999, 修改配置文件, 重启Atlas即可.
来源:博客园 【码农开花】一起学习成长
我会一直分享Java干货,也会分享免费的学习资料课程和面试宝典
回复:【计算机】【设计模式】【面试】有惊喜哦
原文转载:http://www.shaoqun.com/a/499918.html
执御:https://www.ikjzd.com/w/717.html
华翰物流:https://www.ikjzd.com/w/1799
败欧洲:https://www.ikjzd.com/w/1555
1.1MHA简介1.1.1MHA软件介绍 MHA(MasterHighAvailability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在10~30秒之内自动完成数据库的故障切换操作,并且在进行
primc:primc
cbo:cbo
世界游网目的地嘉选:沙迦有望迎来中东旅游投资新局面:世界游网目的地嘉选:沙迦有望迎来中东旅游投资新局面
海南三亚椰梦长廊要收门票吗?好玩吗?:海南三亚椰梦长廊要收门票吗?好玩吗?
BuzzSumo:BuzzSumo
No comments:
Post a Comment