由于开发工作的需要把数据从Hive导入到Elasticsearch,最开始使用了java写了个程序跑数据,80W的数据跑了2个小时左右,想想1000W数据那得要一天的时间,这效率到一次痛苦一次,就放弃了最初的想法,找到了用了hive的的方法,直接把数据导入到elasticsearch,以下是创建过程。
1,准备工作,准备jar包elasticsearch-hadoop-7.1.1,org.apache.commons.httpclient-3.1.jar
2,在hive中添加jar包。


3,建立一张和es连接的表hiveToEsTable.
1 CREATE EXTERNAL TABLE temp.hiveToEsTable ( 2 id, 3 uscc string, 4 remov_dt string, 5 lpr_cert_num string, 6 cont_tel string, 7 license_no string, 8 license_item string, 9 license_begin_dt string,10 license_end_dt string,11 license_fz_dt string,12 license_certi_stat string,13 remov_reas string,14 KEY string15 ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES (16 ##es的索引17 'es.resource' = 'es_index',18 ##es的id19 'es.mapping.id' = 'id',20 'es.mapping.date.rich' = 'false',21 'es.write.operation' = 'upsert',22 ##es所在的ip23 'es.nodes' = '192.168.0.199',24 ##es端口25 'es.port' = '9200'26 );
4.把要添加的es的数据插入到上面建立的表中。即可自动完成数据的同步操作。
INSERT overwrite TABLE temp.hiveToEsTable SELECT id, uscc string, remov_dt string, lpr_cert_num string, cont_tel string, license_no string, license_item string, license_begin_dt string, license_end_dt string, license_fz_dt string, license_certi_stat string, remov_reas string, KEY stringFROM csum.sourceTable
5,导入80w的成果,只要470秒
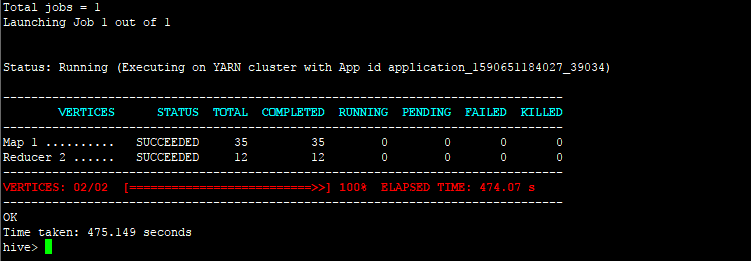
在这次导入的过程中踩到的坑,由于Hive是以前就安装的,使用的是系统自带的Java环境,默认是/usr/lib/jdk,版本是jdk7,但是es7要求的是jdk,我就在原来系统上引入了一个jdk8,安装路径是在/usr/lib/java8,然后知道es的java环境到8,造成两边jdk版本不一致从而导入在创建关联时产生错误。解决方法,①可以把hive 的也指定到jdk8上来,但需要修改配置文件。②把自带的jdk替换成jdk8,es不需要配置jdk8的指定,使用的就是系统默认的。

No comments:
Post a Comment