1. 前言
线程池是JAVA开发中最常使用的池化技术之一,可以减少线程资源的重复创建与销毁造成的开销。
2. 灵魂拷问:怎么做到线程重复利用?
很多同学会联想到连接池,理所当然的说:需要的时候从池中取出线程,执行完任务再放回去。
如何用代码实现呢?
此时就会发现,调用线程的start方法后,生命周期就不由父线程直接控制了。线程的run方法执行完成就销毁了,所谓的"取出"和"放回"只不过是想当然的操作。
这里先说答案:生产者消费者模型
3. ThreadPoolExecutor的实现
3.1 结构
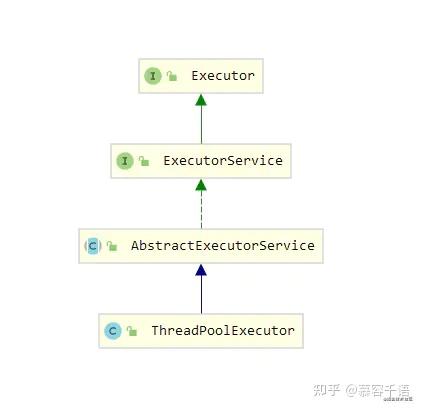
首先看下ThreadPoolExecutor的继承结构
顶级接口是Executor,定义execute方法
ExecutorService添加了submit方法,支持返回future获取执行结果,以及线程池运行状态的相关方法
本文着重讲线程池的执行流程,因此将暂时忽略线程池的状态相关的代码,也建议新手看源码时从核心流程看起。
3.2 核心方法:execute()
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); // 判断是否小于核心线程数 if (workerCountOf(c) < corePoolSize) { //添加worker,添加成功则退出 if (addWorker(command, true)) return; c = ctl.get(); } // 核心线程数已用完则放入队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 双重检查,避免入队完成后,所有线程已销毁,导致没有消费者消费当前任务 if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 队列已满则开启非核心线程,达到最大线程数则使用拒绝策略 else if (!addWorker(command, false)) reject(command); }
execute方法就是一个生产的过程,主要分为开启线程和入队
开启线程会传入command(即当前任务),开启的线程会立即消费该任务
入队的任务则会由Worker消费
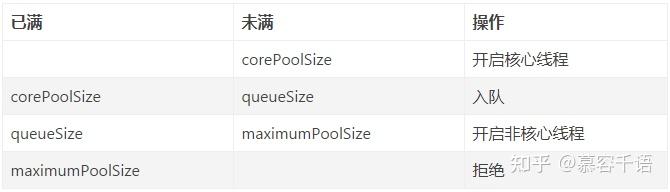
主要关注corePoolSize,maximumPoolSize,queueSize(任务队列长度),workerCount(当前worker数量)这几个参数,可以总结为以下:
3.2 消费者:Worker
Worker类实现Runnable接口,继承AQS,主要先关注thread和firstTask两个属性和run方法
Worker(Runnable firstTask) { setState(-1); this.firstTask = firstTask; this.thread = getThreadFactory().newThread(this);}
从Worker的构造方法可以看出,thread就是线程池中真正消费任务的线程,创建时会传入this(即Worker对象),而Worker实现了Runnable,因此线程运行时就是执行了Worker的run方法。
final void runWorker(Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null; w.unlock(); boolean completedAbruptly = true; try { // 重点关注 while (task != null || (task = getTask()) != null) { // ··· try { beforeExecute(wt, task); Throwable thrown = null; try { // 重点关注 task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error(x); } finally { afterExecute(task, thrown); } } finally { // 重点关注 task = null; // ··· } } completedAbruptly = false; } finally { processWorkerExit(w, completedAbruptly); }}
再来看run方法,直接调用了ThreadPoolExecutor的runWorker方法,runWorker中有一个while循环,循环体执行了task.run方法
task首先会获取Worker中的firstTask属性,并将其置为null,因此firstTask只会执行一次,后续task将通过getTask方法获取。
因此Worker的工作流程可以概括为:消费完Worker的firstTask后,循环执行getTask获取任务并消费,获取不到task时,就退出循环,线程销毁。
此处便可以看出生产者消费者模型了。
private Runnable getTask() { boolean timedOut = false; for (;;) { int c = ctl.get(); // ··· int wc = workerCountOf(c); boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) // 此处返回null,runWorker将退出循环 return null; continue; } try { Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; timedOut = true; } catch (InterruptedException retry) { timedOut = false; } }}
runWorker方法退出循环的条件是getTask返回null。
观察getTask,只有同时满足以下情况时才会返回null

返回的task是通过workQueue.poll和workQueue.take得到的
两者执行时线程均会挂起,直至workQueue中有新的任务
不同之处在于poll方法阻塞keepAliveTime时间后会自动唤醒并返回null,此时timeOut置为true,即满足条件1
private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); // ··· for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); // ··· } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { w = new Worker(firstTask); final Thread t = w.thread; if (t != null) { // ··· if (workerAdded) { t.start(); workerStarted = true; } } } finally { // ··· } return workerStarted;}
了解了Worker之后,再来看execute中调用的addWorker方法
方法有两个参数,firstTask即为Worker的firstTask,core则标记需要新增的是否是核心线程
retry循环与线程池状态相关,内层for循环则是重复尝试cas增加线程,若大于corePoolSize或者maximumPoolSize则新增失败,cas成功后,new一个Worker并start
3.3 总结
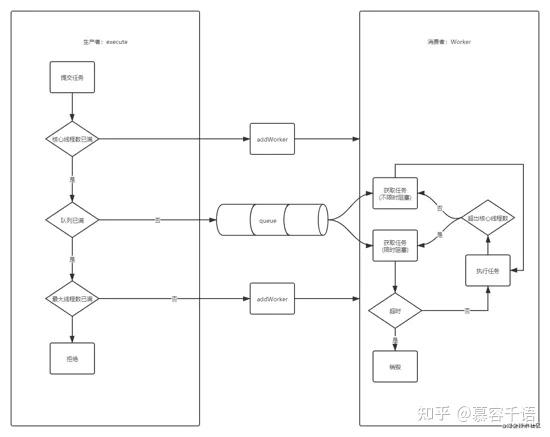
回到最初的问题,线程是如何做到重复利用的?
并不存在取出线程使用完再归还的操作,线程启动后进入循环,主动获取任务执行,退出循环则线程销毁。
execute方法控制新增Worker和任务入队
附:手写简易线程池
public class MyThreadPool implements Executor { private int corePoolSize; private int maximumPoolSize; private BlockingQueue<Runnable> queue; //记录当前工作线程数 private AtomicInteger count; private long keepAliveTime; private RejectHandler rejectHandler; public MyThreadPool(int corePoolSize, int maximumPoolSize, BlockingQueue<Runnable> queue, long keepAliveTime, RejectHandler rejectHandler) { this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.queue = queue; this.keepAliveTime = keepAliveTime; this.rejectHandler = rejectHandler; count = new AtomicInteger(0); } @Override public void execute(Runnable task) { int ct = count.get(); //核心线程数未满,尝试增加核心线程 if (ct < corePoolSize && count.compareAndSet(ct, ct + 1)) { new Worker(task).start(); return; } //入队 if (queue.offer(task)) { return; } //队列已满,尝试增加非核心线程 if (ct < maximumPoolSize && count.compareAndSet(ct, ct + 1)) { new Worker(task).start(); return; } //已达最大线程数,拒绝 rejectHandler.reject(task); } class Worker extends Thread { Runnable firstTask; public Worker(Runnable firstTask) { this.firstTask = firstTask; } @Override public void run() { Runnable task = firstTask; firstTask = null; while (true) { try { //getTask会阻塞 if (task != null || (task = getTask()) != null) { task.run(); } else { //getTask超时才会进入,直接退出,线程销毁 break; } } catch (InterruptedException e) { e.printStackTrace(); } finally { //置空,否则不能getTask task = null; } } } } Runnable getTask() throws InterruptedException { //标记是否超时过 boolean timedOut = false; while (true) { int ct = count.get(); //超出核心线程数才进入超时逻辑,即使timeOut由于线程poll超时过一次变成true,执行到这里如果不超出corePoolSize,可以再次进入take分支 if (ct > corePoolSize) { //超出核心线程数 if (timedOut) { //已超时过,尝试减少工作线程数,失败会continue,然后重新比较corePoolSize,重试减少线程数 if (count.compareAndSet(ct, ct - 1)) { return null; } else { continue; } } Runnable task = queue.poll(keepAliveTime, TimeUnit.MILLISECONDS); if (task == null) { //poll超时才进入 timedOut = true; continue; } return task; } else { //必然能获取到task return queue.take(); } } } public static interface RejectHandler { void reject(Runnable r); } public static void main(String[] args) { MyThreadPool pool = new MyThreadPool(2, 5, new LinkedBlockingQueue<>(100), 2000, r -> { System.out.println(r + ": reject"); }); for (int i = 0; i < 3; i++) { final int x = i; new Thread(() -> { for (int j = 0; j < 5; j++) { final int y = j; pool.execute(() -> { try { Thread.sleep(3000L); } catch (InterruptedException e) { e.printStackTrace(); } LocalDateTime now = LocalDateTime.now(); System.out.println(String.format("线程i=%s, j=%s,执行结束: %s", x, y, now.format(DateTimeFormatter.ISO_DATE_TIME))); }); } }).start(); } }}
干货来袭!阿里内部Java面试必备软/硬实力+大厂面经全都有
有完整的Java初级,高级对应的学习路线和资料!专注于java开发。分享java基础、原理性知识、JavaWeb实战、spring全家桶、设计模式、分布式及面试资料、开源项目,助力开发者成长!
欢迎关注微信公众号:码邦主
原文转载:http://www.shaoqun.com/a/603645.html
巴克莱银行:https://www.ikjzd.com/w/2775
aeo:https://www.ikjzd.com/w/2356
1.前言线程池是JAVA开发中最常使用的池化技术之一,可以减少线程资源的重复创建与销毁造成的开销。2.灵魂拷问:怎么做到线程重复利用?很多同学会联想到连接池,理所当然的说:需要的时候从池中取出线程,执行完任务再放回去。如何用代码实现呢?此时就会发现,调用线程的start方法后,生命周期就不由父线程直接控制了。线程的run方法执行完成就销毁了,所谓的"取出"和"放回"只不过是想当然的操作。这里先说答
环球华网:https://www.ikjzd.com/w/1063
tradeindia:https://www.ikjzd.com/w/2305
promoted:https://www.ikjzd.com/w/971
亚马逊黄金日购物意愿降低?电子商务整体搜索量下降84%:https://www.ikjzd.com/home/132109
阿里九月采购节上线"3D虚拟家装",大家装行业成交增长130%:https://www.ikjzd.com/home/129927
亚马逊旺季产品布局思路:https://www.ikjzd.com/tl/107778
No comments:
Post a Comment